
Automate with AI

Kubermatic AI PaaS: Maximum GPU ROI, Zero Lock-In
Situation
Raw Compute Is Not Enough
Enterprises are moving fast on AI, but most hit the same wall. GPU clusters are procured, pilots are running, yet production AI at scale remains out of reach. The problem is not compute, it is the lack of a unified software layer to orchestrate distributed workloads, manage multi-tenant isolation, and enforce governance.
Closing that gap isn’t just an operational priority, it’s a strategic one. Gartner puts it plainly:
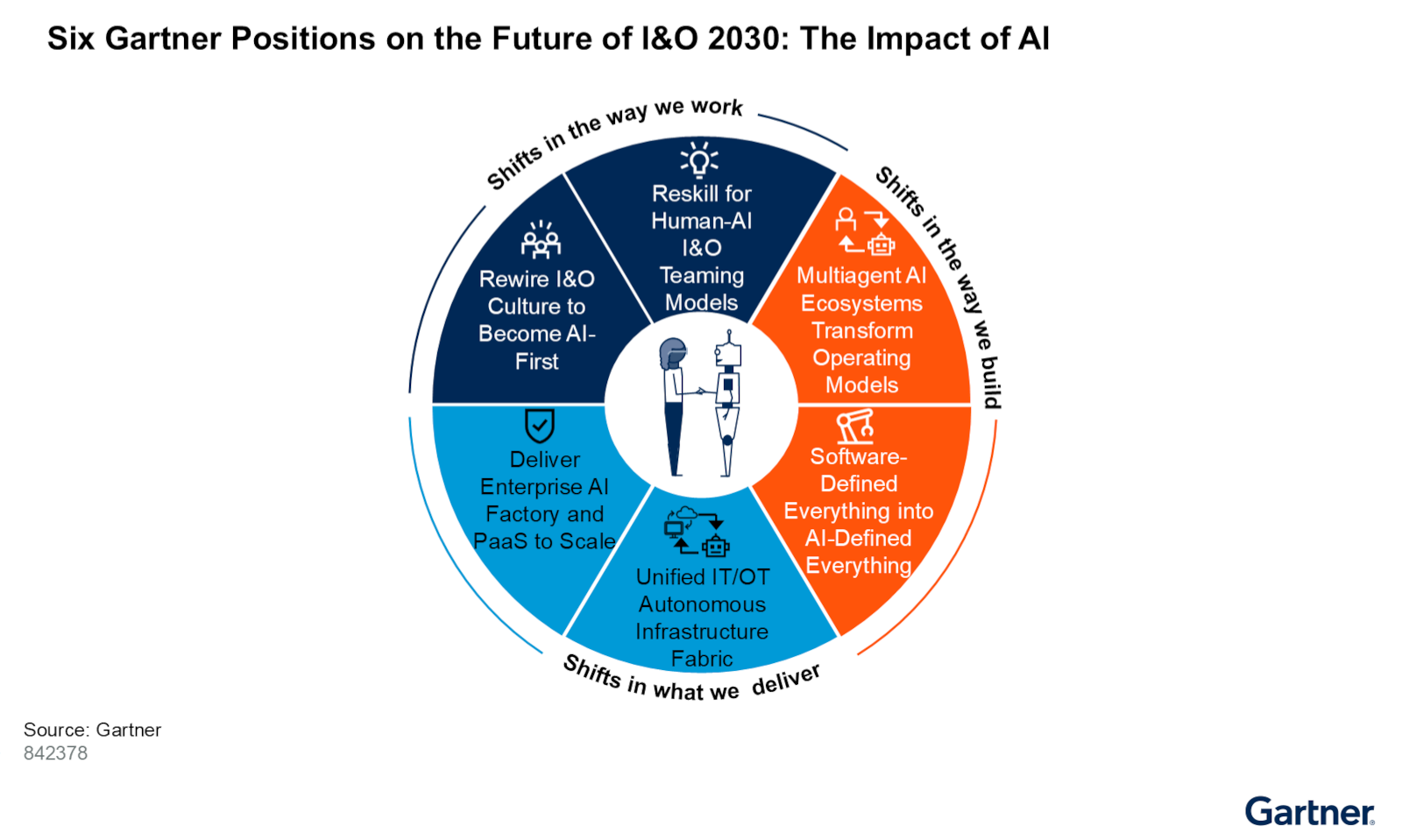
The Challenge:
- Operational silos: Data science, IT, and security teams operate with separate tools and environments, leaving expensive GPU resources chronically underutilised.
- The deployment bottleneck: Moving a model from training to production requires manual handoffs and inconsistent environments, stretching cycles from days to weeks.
- The governance gap: Without centralised visibility and policy enforcement, AI workloads proliferate across environments, creating compliance exposure and uncontrolled costs.
How we help
Kubermatic as Your AI Factory Operating System
Kubermatic transforms disparate GPU infrastructure — bare metal, on-premises, or hybrid multi-cloud — into a cohesive, self-service AI factory. Data scientists get instant self-service access. Platform engineers retain granular control over high-value GPU resources. Everyone works from the same platform.
Self-Service Developer Portal
Data science teams provision logical Kubernetes workspaces instantly via a natural language AI agent that translates prompts into configurations. Teams focus on models, not cluster administration.
GPU Orchestration
Native NVIDIA GPU Operator integration ensures AI workloads access GPU resources directly, bypassing hypervisor overhead. Bare-metal provisioning is fully automated.
High-Performance Workloads
Disaggregated inference splits LLM workloads into prefill and decode phases, scaling independently to increase throughput without additional hardware. HPC-grade gang scheduling handles massive training jobs with deterministic, topology-aware placement, eliminating the deadlocks standard Kubernetes schedulers cannot resolve.
AI Network Fabric
An AI-aware load balancer routes inference traffic based on real-time GPU telemetry and cache saturation with semantic caching, token rate limits, and prompt guardrails enforced at the network layer.
Security
LLM API keys and model credentials are managed with automated, zero-downtime rotation via Kubermatic SecureGuard.
Use Cases
Enterprise AI Factory
- The Mission: Eliminate silos between IT, security, and data science without sacrificing governance or GPU utilisation.
- The Application: Self-service GPU workspaces for data scientists, centralised resource quotas and policy controls for platform teams, and automated lifecycle management for all AI workloads — training, fine-tuning, and inference — from one control plane.
Neocloud Providers: From Bare Metal to Managed AI Service
- The Mission: Move from low-margin GPU leasing to a high-margin, turn-key enterprise AI platform.
- The Application: Kubermatic sits directly atop bare-metal GPU infrastructure, automating provisioning and exposing a self-service portal so enterprise customers deploy RAG pipelines and inference endpoints instantly without hardware management overhead.
Sovereign AI
- The Mission: Train and deploy AI on fully sovereign, on-premises infrastructure with strict data residency and no foreign cloud dependencies.
- The Application: Kubermatic deploys entirely on-premises or air-gapped. SecureGuard protects credentials with automated rotation. HPC scheduling maximises utilisation of limited local GPU pools. Data never leaves the controlled environment.
Telecommunications: Legacy Networks Meet Edge AI
- The Mission: Run legacy VM-based network functions and modern AI workloads on the same infrastructure without separate stacks or teams.
- The Application: Kubermatic Virtualization encapsulates traditional VMs into Kubernetes pods, running them alongside containerised AI inference workloads at the network edge — managed centrally across thousands of distributed sites.
Outcome
Maximum GPU ROI and Fluid Portability
By standardizing on the Kubermatic AI PaaS, enterprises replace fragmented environments with a unified, open software layer that maximizes hardware value and accelerates delivery.
Maximum GPU Utilisation
Intelligent scheduling and disaggregated inference eliminate idle GPU time across teams.
Weeks to Hours Deployment
Automated lifecycle management removes manual handoffs, cutting deployment cycles from weeks to hours.
Governed AI at Scale
Centralised policy enforcement and audit trails across every workload and environment.
No Lock-In
Kubernetes AI Conformance guarantees workloads are freely portable across Neoclouds, private clouds, and on-premises — wherever GPU costs are lowest.
Why Kubermatic?

Proven Leadership
Recognized by Gartner®, Forrester, GigaOM, SPARK Matrix™ and a top contributor to the CNCF.

Flexibility
Supports Bare Metal, vSphere, OpenStack, and all major public clouds (AWS, Azure, GCP).

Sovereignty
Germany-based company offering 100% sovereign infrastructure and secure, private cloud stacks.

Expert Support
Implementation, managed services, and 24×7 mission support from Kubernetes experts.